
在分布式的环境中,许多服务依赖不可避免的会出现失败,Hystrix[hɪst’rɪks] 就是一个通过增加延迟容忍和容错逻辑来控制这些分布式服务之间的交互的库,它主要通过隔离服务之间的访问点、停止跨服务之间的级联故障以及提供后备选项来提高系统的整体弹性。
hystrix的设计是为了做到以下几点
- 通过第三方客户端库,从依赖项(通常通过网络)获得保护,并控制延迟和失败
- 在复杂的分布式系统中停止级联故障
- 快速失败并及时恢复
- 在可能的情况下,优雅的降级
- 能够实时监控,支持报警及操作控制
hystrix解决了什么问题
在一个复杂的分布式应用程序中可能有几十个甚至更多的依赖服务,它们中的每一个都有可能在某一时刻发生故障,如果不能将这些故障从应用程序中分离出来,很可能导致当前应用的不可用。
例如,对于一个依赖于30个服务的应用程序,每个服务有99.99%的正常运行时间,理想情况下我们可以做如下推算(现实有可能更糟糕):
- 99.9930 = 99.7% ,应用程序有 99.7% 的正常运行时间
- 0.3% * 10000 0000 = 30 0000,每1亿个请求有30万个会失败
- 0.3% * 24 * 30 = 2.16 ,每个月有2小时的时间服务不可用
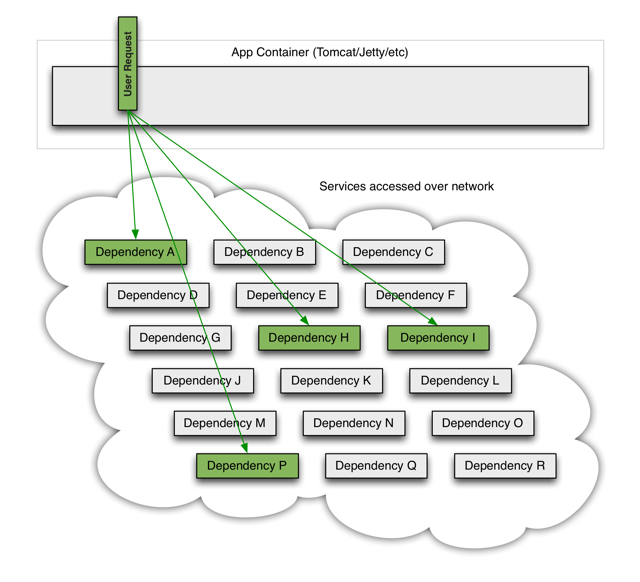
即使所有的依赖关系都能很好地完成,每一项服务的总影响甚至是0.01%的停机时间,如果你不设计出整个系统来恢复弹性,那么它就相当于一个月的停机时间。当一切正常时,请求流就像下图所示
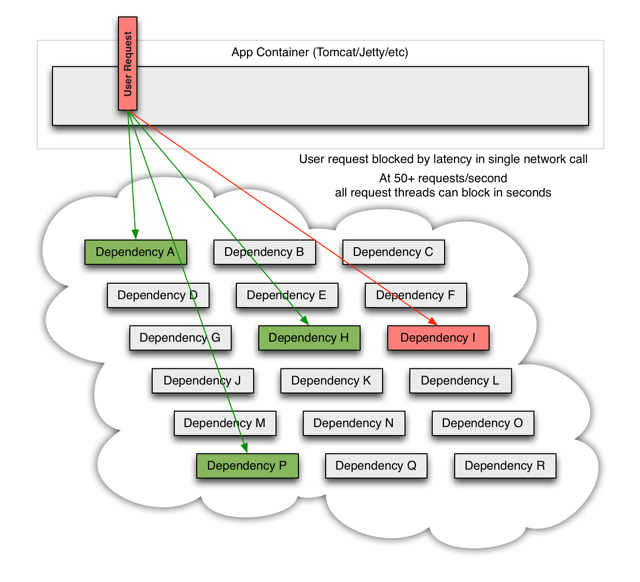
当其中一个服务出现问题时,它可以阻塞整个用户请求
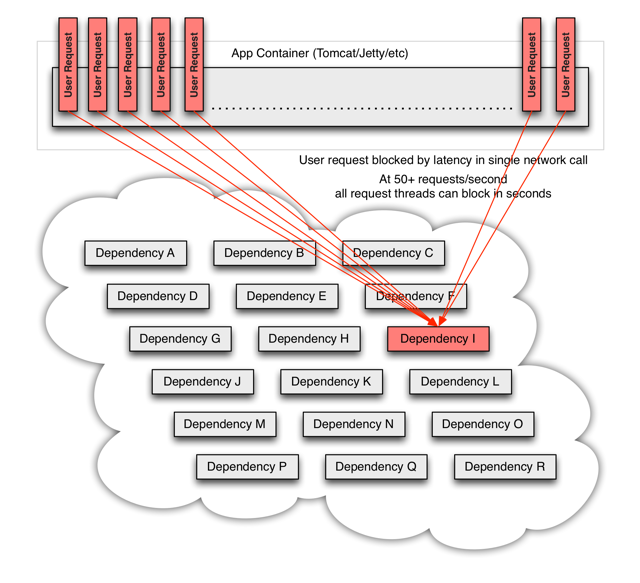
在流量比较大的情况下,一个服务的故障可能导致其他服务的延迟增加,系统队列、线程等资源饱和,甚至整个系统的不可用
其他
